 By Medium -
2021-03-22
By Medium -
2021-03-22
Google Data Studio is a tool I have been using more and more in the past few months. With the high usage, I have come to notice its advantages over other tools, its capabilities, but also its’…
 By Google Cloud Blog -
2021-03-12
By Google Cloud Blog -
2021-03-12
Among the best ways to prevent data loss are to modify, delete, or never collect the data in the first place.
 By Docs -
2021-01-24
By Docs -
2021-01-24
Describes benefits, challenges, and best practices for Big Data architectures on Azure.
 By Medium -
2020-12-01
By Medium -
2020-12-01
If I learned anything from working as a data engineer, it is that practically any data pipeline fails at some point. Broken connection, broken dependencies, data arriving too late, or some external…
 By Forbes -
2020-12-22
By Forbes -
2020-12-22
2020 was a year like no other, but the silver lining of a changed world brought data quality, speed, and insights to the forefront for businesses. Here’s what’s coming next.
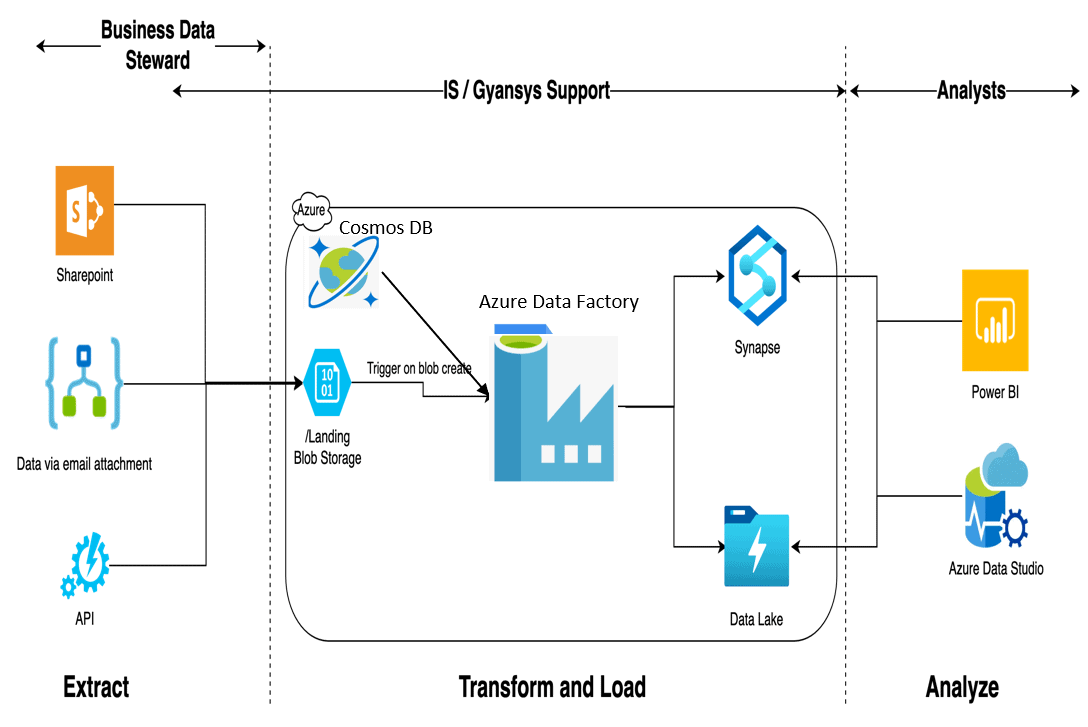 By SQLServerCentral -
2021-03-09
By SQLServerCentral -
2021-03-09
Azure Data Factory (ADF) is a cloud based data integration service that allows you to create data-driven workflows in the cloud for orchestrating and
