 By facebook -
2021-03-05
By facebook -
2021-03-05
The future of AI is in creating systems that can learn directly from whatever information they’re given — whether it’s text, images, or another type of...
 By Medium -
2020-10-23
By Medium -
2020-10-23
Transformer Language Modeling for Akuapem and Asante Twi
By Joe Davison Blog -
2020-05-29
State-of-the-art NLP models for text classification without annotated data
 By Medium -
2021-02-19
By Medium -
2021-02-19
HugginFace has been on top of every NLP(Natural Language Processing) practitioners mind with their transformers and datasets libraries. In 2020, we saw some major upgrades in both these libraries…
By facebook -
2021-03-05
How can we build machines with human-level intelligence? There’s a limit to how far the field of AI can go with supervised learning alone. Here's why...
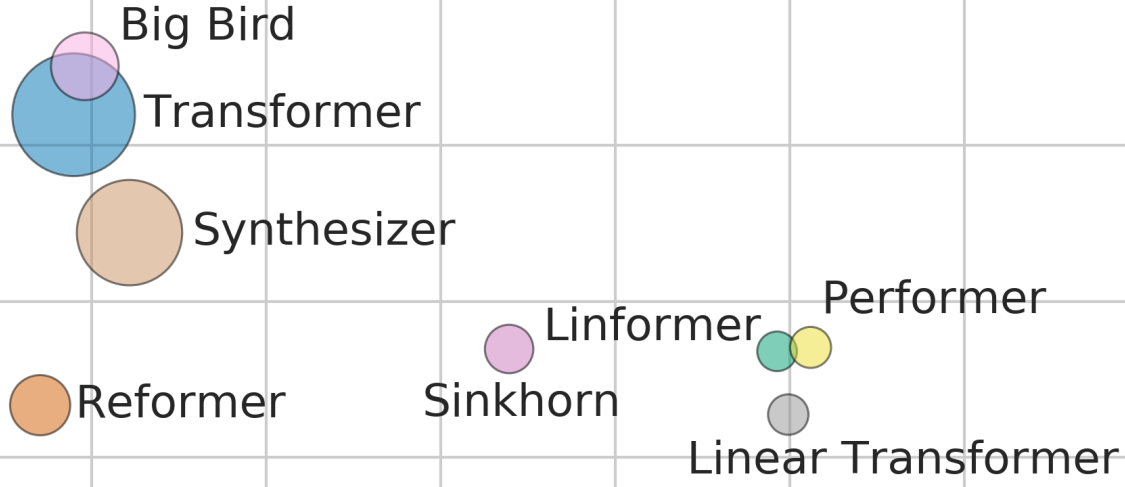 By Sebastian Ruder -
2021-01-19
By Sebastian Ruder -
2021-01-19
This post summarizes progress in 10 exciting and impactful directions in ML and NLP in 2020.
