 By Medium -
2021-02-18
By Medium -
2021-02-18
In our last post we took a broad look at model observability and the role it serves in the machine learning workflow. In particular, we discussed the promise of model observability & model monitoring…
 By Medium -
2020-12-03
By Medium -
2020-12-03
This tutorial covers the entire ML process, from data ingestion, pre-processing, model training, hyper-parameter fitting, predicting and storing the model for later use. We will complete all these…
 By Medium -
2020-11-05
By Medium -
2020-11-05
Here is what you tell them.
 By datasciencecentral -
2020-12-22
By datasciencecentral -
2020-12-22
A few years ago, it was extremely uncommon to retrain a machine learning model with new observations systematically. This was mostly because the model retrain…
 By Amazon Web Services -
2021-02-19
By Amazon Web Services -
2021-02-19
This post is co-authored by Jiahang Zhong, Head of Data Science at Zopa. Zopa is a UK-based digital bank and peer to peer (P2P) lender. In 2005, Zopa launched the first ever P2P lending company to gi ...
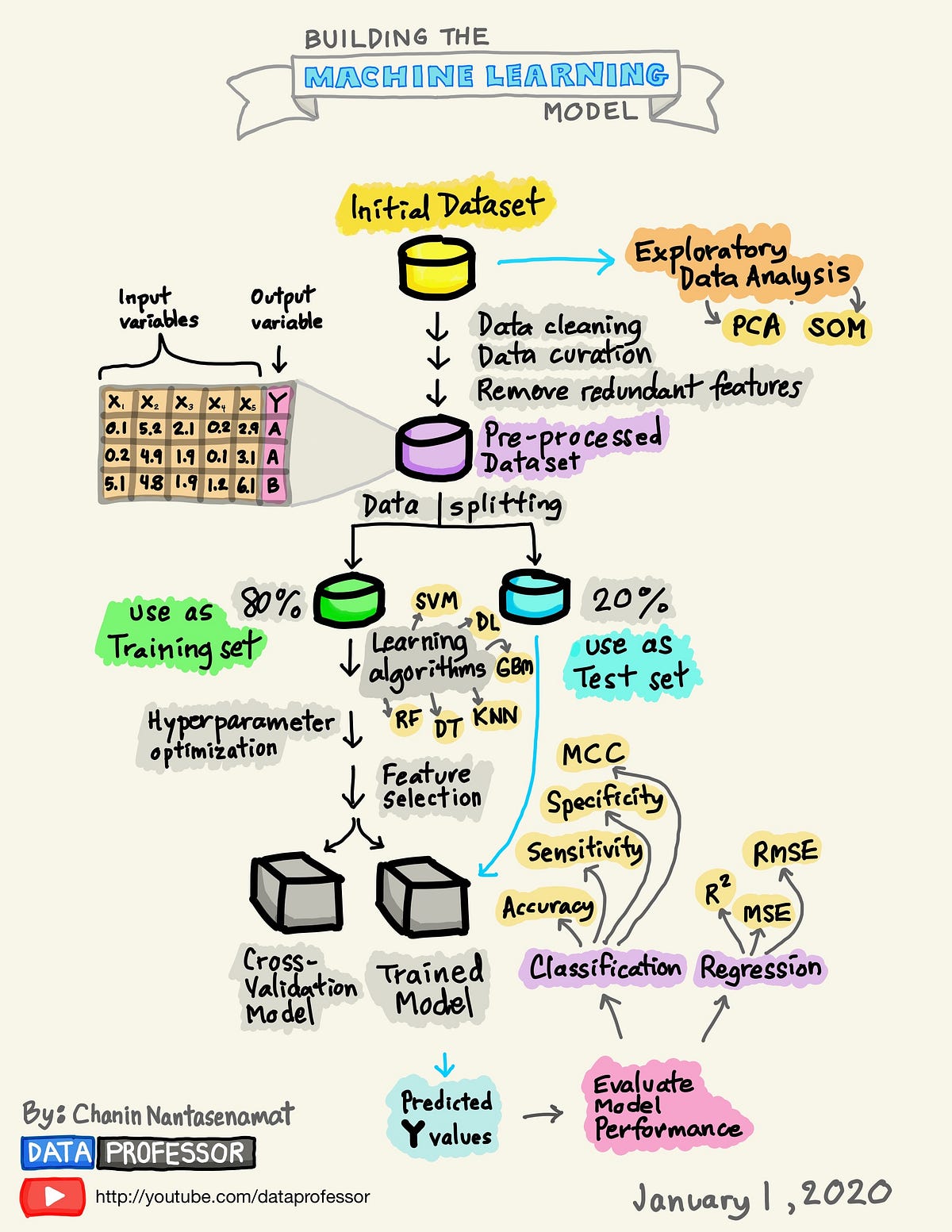 By Medium -
2020-07-25
By Medium -
2020-07-25
A Visual Guide to Learning Data Science
