 By Medium -
2020-12-03
By Medium -
2020-12-03
This tutorial covers the entire ML process, from data ingestion, pre-processing, model training, hyper-parameter fitting, predicting and storing the model for later use. We will complete all these…
 By Medium -
2021-03-18
By Medium -
2021-03-18
Machine Learning is the path to a better and advanced future. A Machine Learning Developer is the most demanding job in 2021 and it is going to increase by 20–30% in the upcoming 3–5 years. Machine…
 By Medium -
2020-07-25
By Medium -
2020-07-25
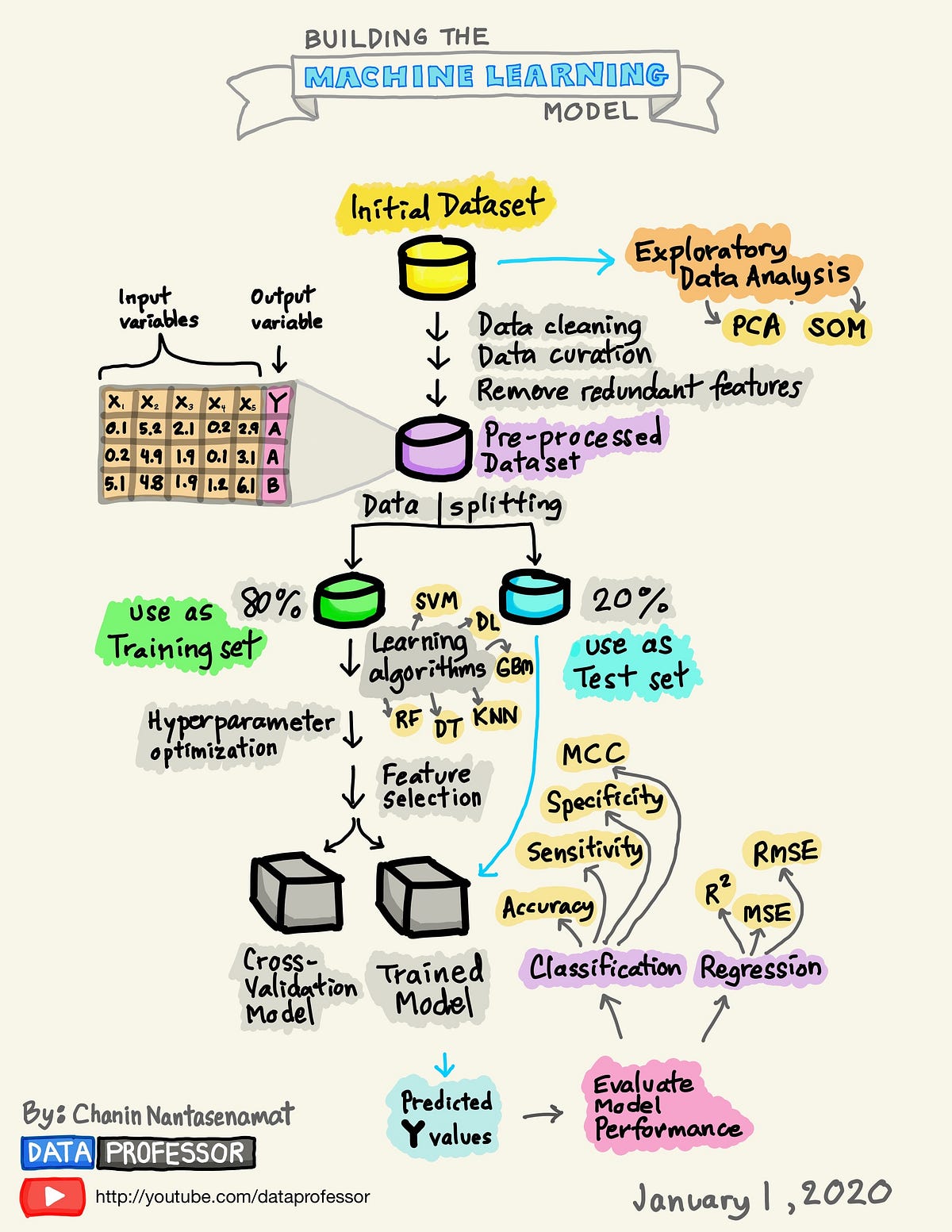
A Visual Guide to Learning Data Science
 By huggingface -
2021-03-12
By huggingface -
2021-03-12
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
 By Medium -
2020-12-08
By Medium -
2020-12-08
As you know, data science, and more specifically machine learning, is very much en vogue now, so guess what? I decided to enroll in a MOOC to become fluent in data science. But when you start with a…
 By Stack Overflow Blog -
2020-10-12
By Stack Overflow Blog -
2020-10-12
The goal of building a machine learning model is to solve a problem, and a machine learning model can only do so when it is in production and actively in use by consumers. As such, model deployment is ...
