 By KDnuggets -
2020-12-15
By KDnuggets -
2020-12-15
An extensive overview of Active Learning, with an explanation into how it works and can assist with data labeling, as well as its performance and potential limitations.
 By Medium -
2020-12-08
By Medium -
2020-12-08
As you know, data science, and more specifically machine learning, is very much en vogue now, so guess what? I decided to enroll in a MOOC to become fluent in data science. But when you start with a…
 By freeCodeCamp.org -
2021-01-12
By freeCodeCamp.org -
2021-01-12
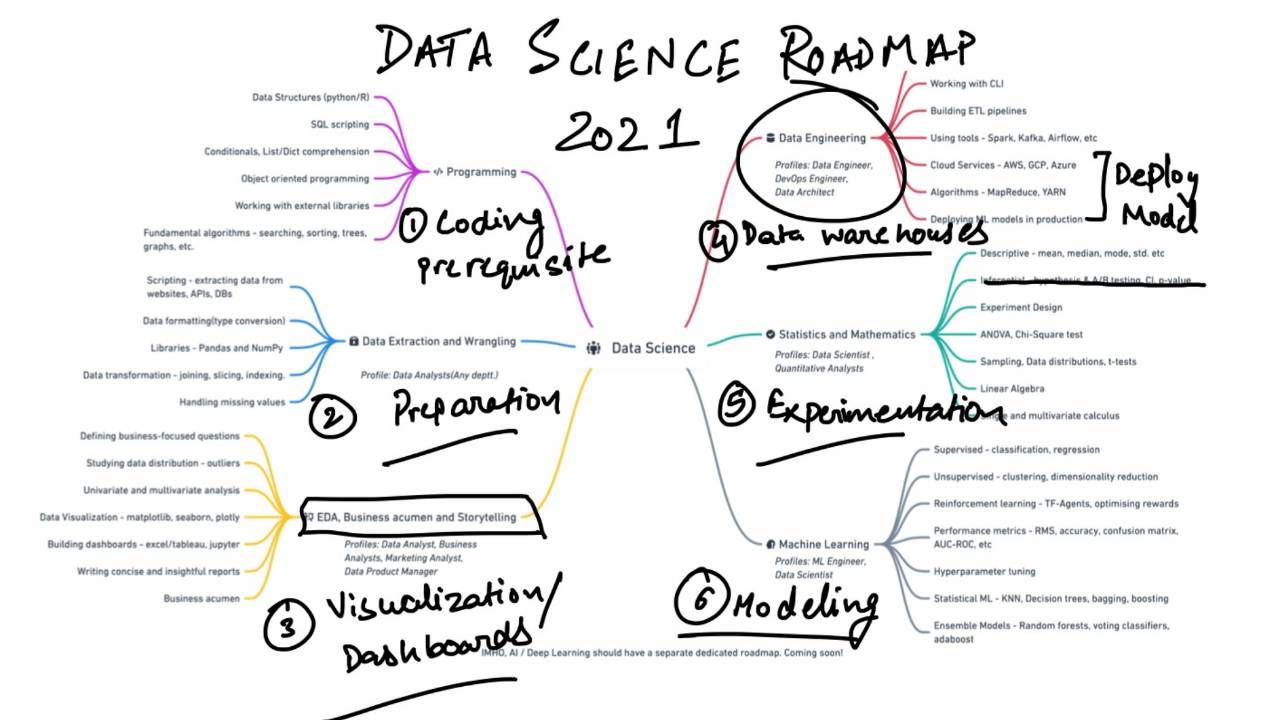
Although nothing really changes but the date, a new year fills everyone with the hope of starting things afresh. If you add in a bit of planning, some well-envisioned goals, and a learning roadmap, yo ...
 By TechTalks -
2021-01-04
By TechTalks -
2021-01-04
Semi-supervised learning helps you solve classification problems when you don't have labeled data to train your machine learning model.
 By Medium -
2021-03-18
By Medium -
2021-03-18
Machine Learning is the path to a better and advanced future. A Machine Learning Developer is the most demanding job in 2021 and it is going to increase by 20–30% in the upcoming 3–5 years. Machine…
 By KDnuggets -
2020-10-13
By KDnuggets -
2020-10-13
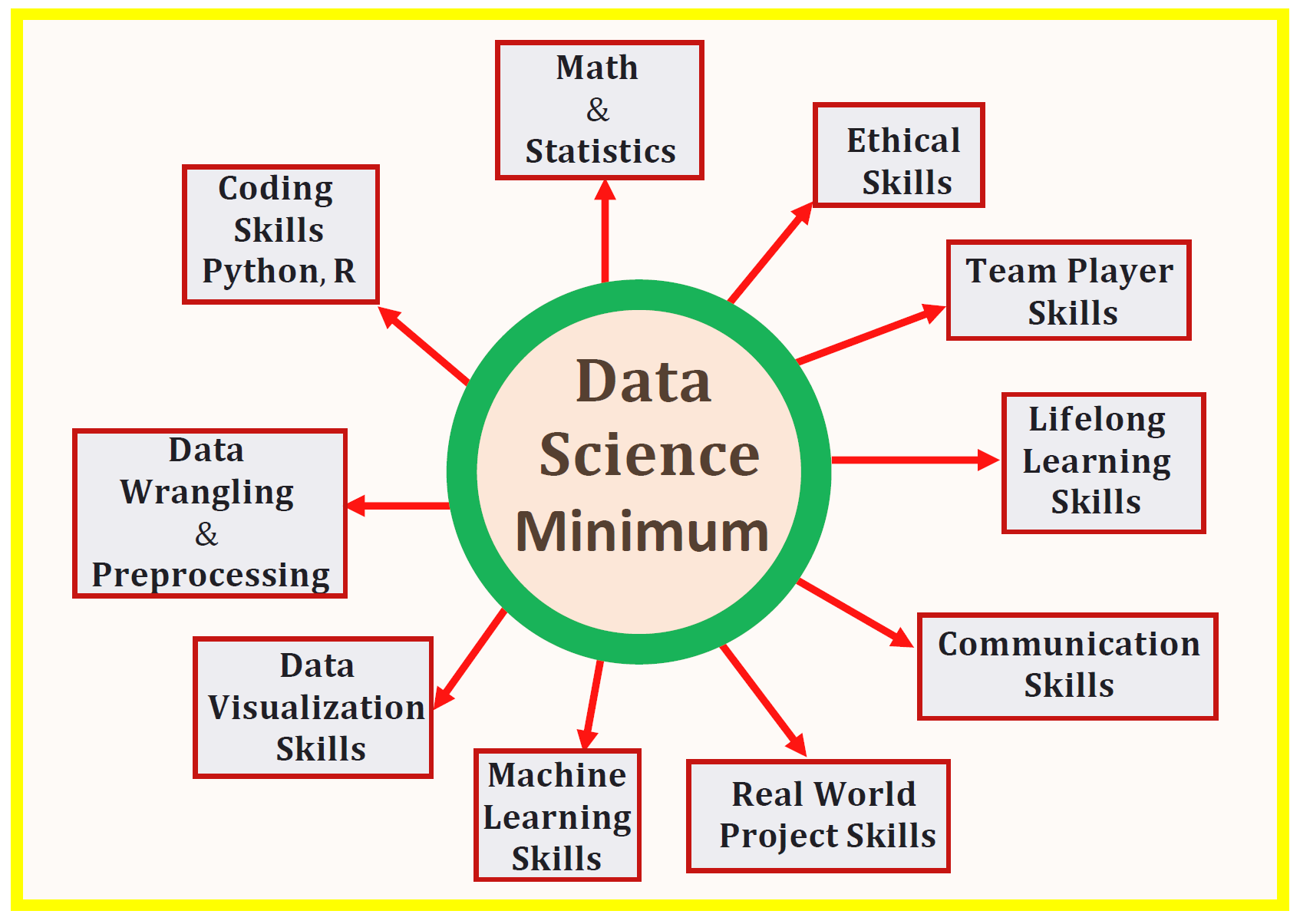
Data science is ever-evolving, so mastering its foundational technical and soft skills will help you be successful in a career as a Data Scientist, as well as pursue advance concepts, such as deep lea ...
