 By Google Cloud Blog -
2021-03-03
By Google Cloud Blog -
2021-03-03
In collaboration with our partner Quantiphi, we developed a smart analytics design pattern that enables you to build a scalable real-time fraud detection solution in one hour using serverless, no-ops ...
 By Medium -
2021-02-16
By Medium -
2021-02-16
If you have worked with any kind of forecasting models, you will know how laborious it can be at times especially when trying to predict multiple variables. From identifying if a time-series is…
 By Stack Overflow Blog -
2020-10-12
By Stack Overflow Blog -
2020-10-12
The goal of building a machine learning model is to solve a problem, and a machine learning model can only do so when it is in production and actively in use by consumers. As such, model deployment is ...
 By Global Cloud Platforms -
2021-02-02
By Global Cloud Platforms -
2021-02-02
Retail businesses have a “goldilocks” problem when it comes to inventory: don’t stock too much, but don’t stock…
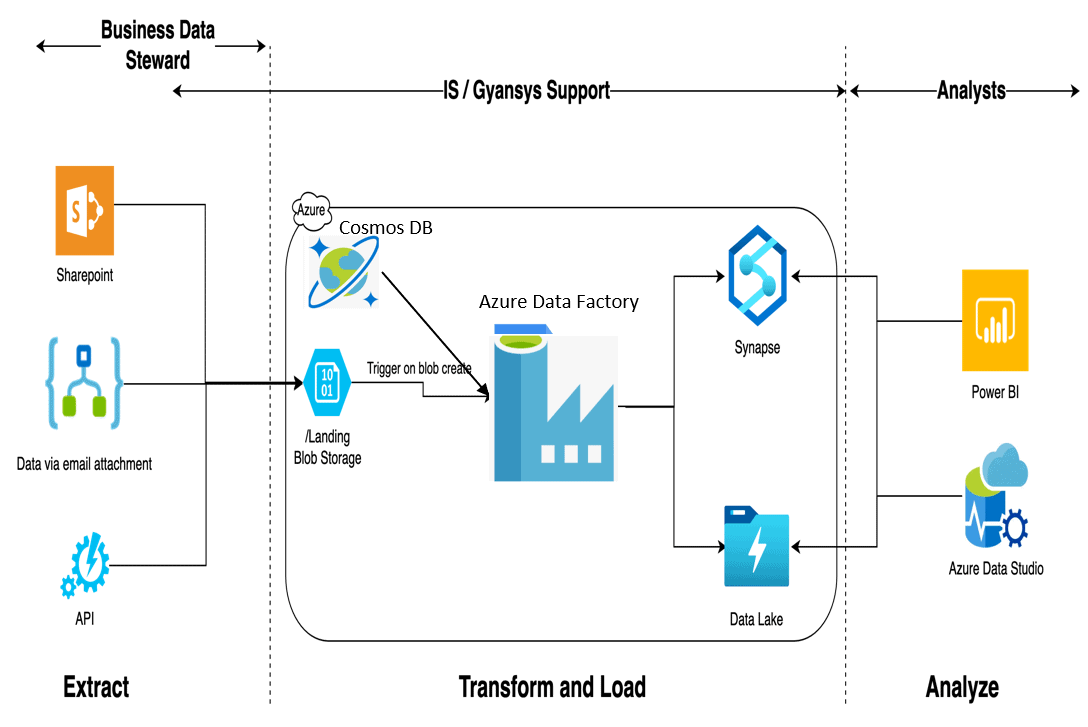 By SQLServerCentral -
2021-03-09
By SQLServerCentral -
2021-03-09
Azure Data Factory (ADF) is a cloud based data integration service that allows you to create data-driven workflows in the cloud for orchestrating and
 By Medium -
2020-12-03
By Medium -
2020-12-03
This tutorial covers the entire ML process, from data ingestion, pre-processing, model training, hyper-parameter fitting, predicting and storing the model for later use. We will complete all these…
