 By Medium -
2021-03-18
By Medium -
2021-03-18
Machine Learning is the path to a better and advanced future. A Machine Learning Developer is the most demanding job in 2021 and it is going to increase by 20–30% in the upcoming 3–5 years. Machine…
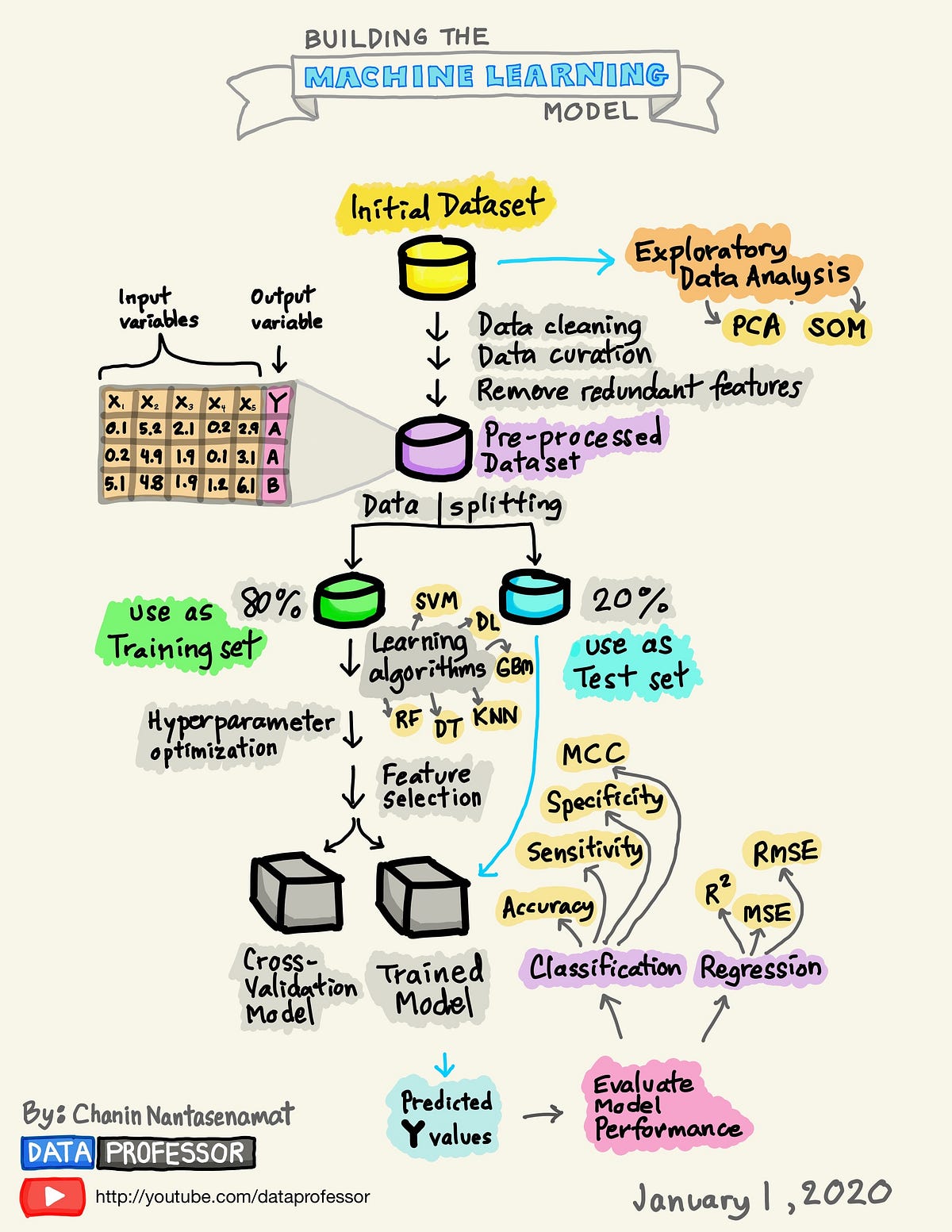 By Medium -
2020-07-25
By Medium -
2020-07-25
A Visual Guide to Learning Data Science
 By Medium -
2021-01-05
By Medium -
2021-01-05
Demonstrating the efficiency of pmdarima’s auto_arima() function compared to implementing a traditional ARIMA model.
 By Joe Davison Blog -
2020-05-29
By Joe Davison Blog -
2020-05-29
State-of-the-art NLP models for text classification without annotated data
 By Medium -
2021-01-04
By Medium -
2021-01-04
A groundbreaking and relatively new discovery upends classical statistics with relevant implications for data science practitioners and…
 By huggingface -
2021-03-12
By huggingface -
2021-03-12
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
