By Medium -
2020-09-28
By Medium -
2020-09-28
Finding machine learning datasets is tenacious indeed, but it doesn’t have to be! In this article, we’ve shared multiple datasets you can…
 By GitHub -
2021-01-05
By GitHub -
2021-01-05
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools - huggingface/datasets
 By Medium -
2021-02-19
By Medium -
2021-02-19
HugginFace has been on top of every NLP(Natural Language Processing) practitioners mind with their transformers and datasets libraries. In 2020, we saw some major upgrades in both these libraries…
 By GitHub -
2021-03-03
By GitHub -
2021-03-03
Language model finetuning on NER with an easy interface, and cross-domain evaluation. We released NER models finetuned on various domain via huggingface model hub. - asahi417/tner
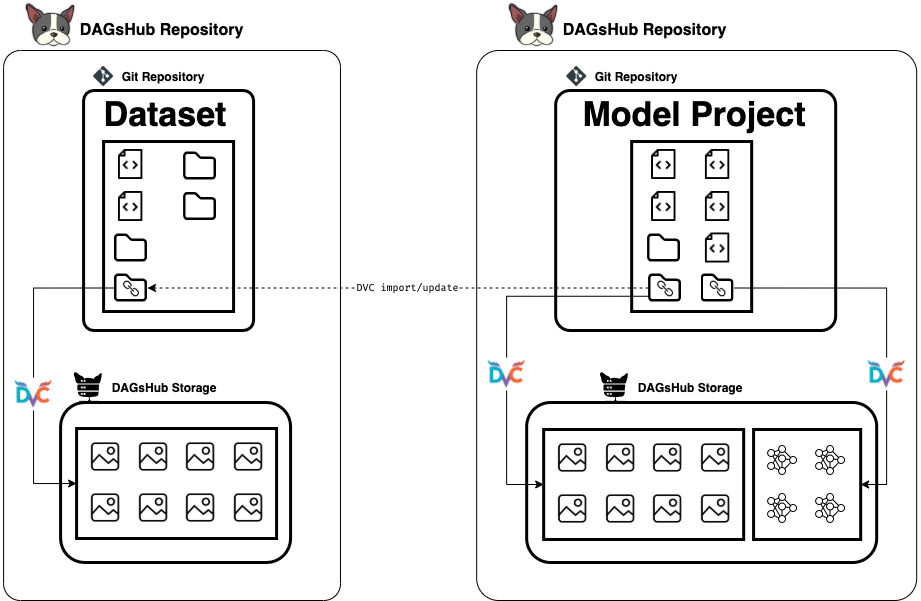 By DAGsHub Blog -
2021-01-18
By DAGsHub Blog -
2021-01-18
Create, maintain, and contribute to a long-living dataset that will update itself automatically across projects, using git and DVC as versioning systems.
 By Machine Learning Mastery -
2020-11-01
By Machine Learning Mastery -
2020-11-01
Random Forest is a popular and effective ensemble machine learning algorithm. It is widely used for classification and regression predictive modeling problems with structured (tabular) data sets, e.g. ...