By Medium -
2020-11-04
By Medium -
2020-11-04
Since the birth of BERT followed by that of Transformers have dominated NLP in nearly every language-related tasks whether it is Question-Answering, Sentiment Analysis, Text classification or Text…
 By Medium -
2020-12-10
By Medium -
2020-12-10
While learning about time series forecasting, sooner or later you will encounter the vastly popular Prophet model, developed by Facebook. It gained lots of popularity due to the fact that it provides…
 By KDnuggets -
2021-01-20
By KDnuggets -
2021-01-20
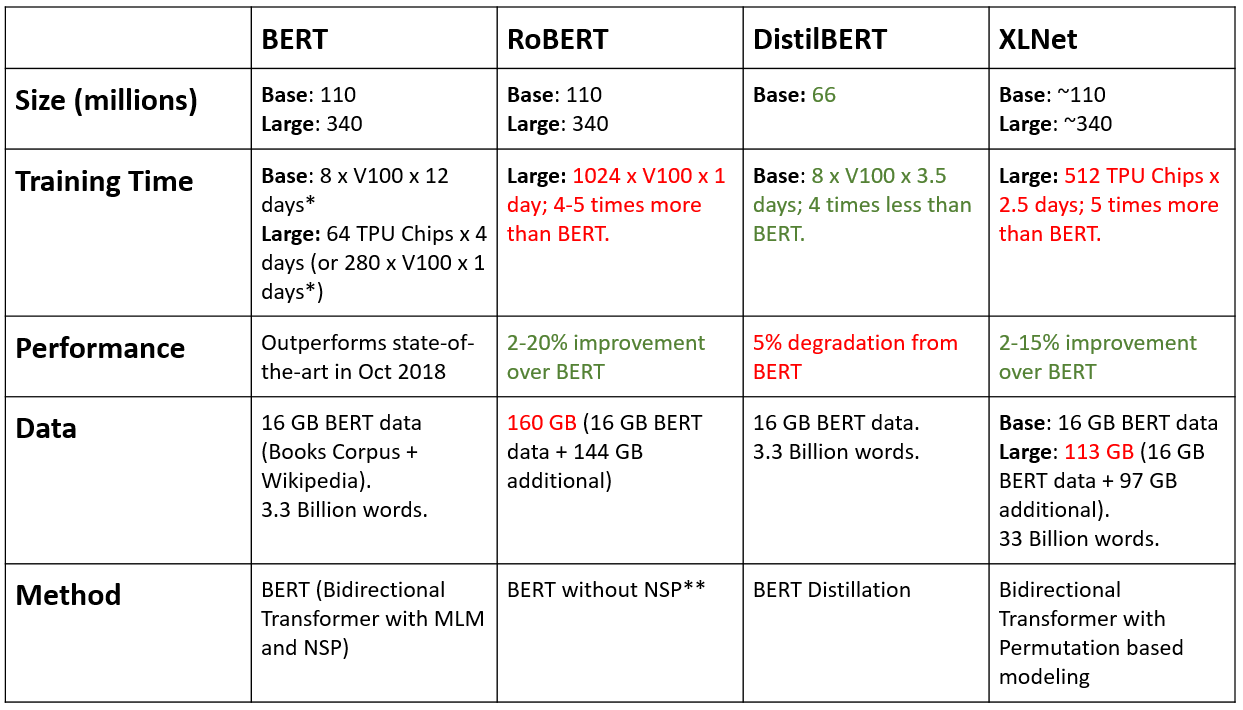
Lately, varying improvements over BERT have been shown — and here I will contrast the main similarities and differences so you can choose which one to use in your research or application.
 By The Gradient -
2020-11-21
By The Gradient -
2020-11-21
A broad overview of the sub-field of machine learning interpretability; conceptual frameworks, existing research, and future directions.
 By Microsoft Research -
2021-01-19
By Microsoft Research -
2021-01-19
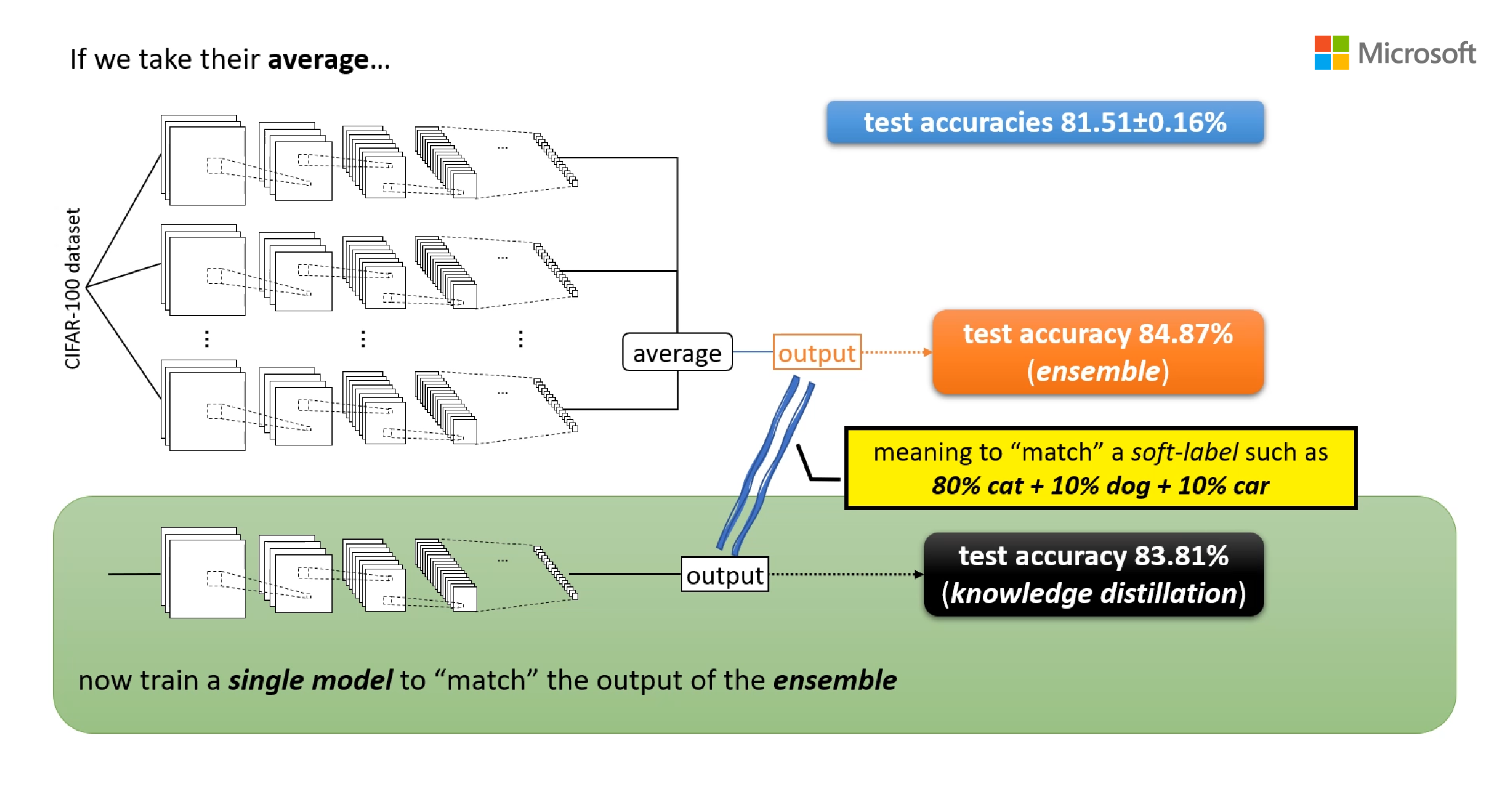
Microsoft and CMU researchers begin to unravel 3 mysteries in deep learning related to ensemble, knowledge distillation & self-distillation. Discover how their work leads to the first theoretical proo ...
 By Medium -
2021-02-02
By Medium -
2021-02-02
How to outperform the benchmark in clothes recognition with fastai and DeepFashion Dataset. How to use fastai models in PyTorch. Code, explanation, evaluation on the user data.