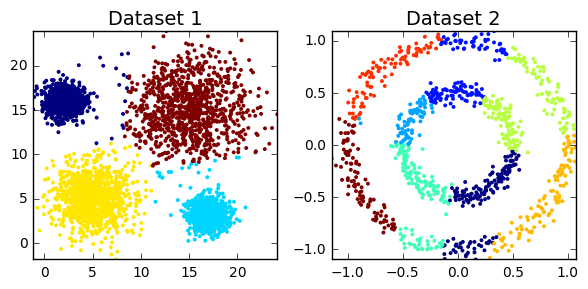
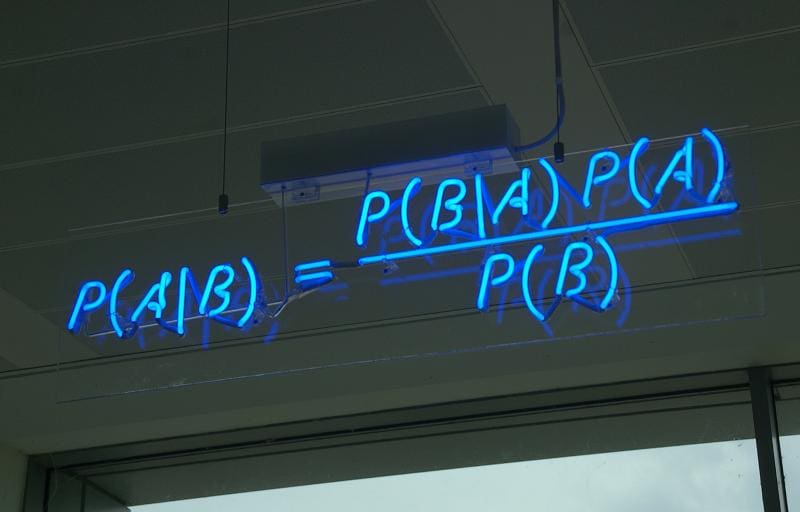By Medium -
2020-11-02
By Medium -
2020-11-02
Big changes to the way graph data science is managed in Neo4j present big opportunity
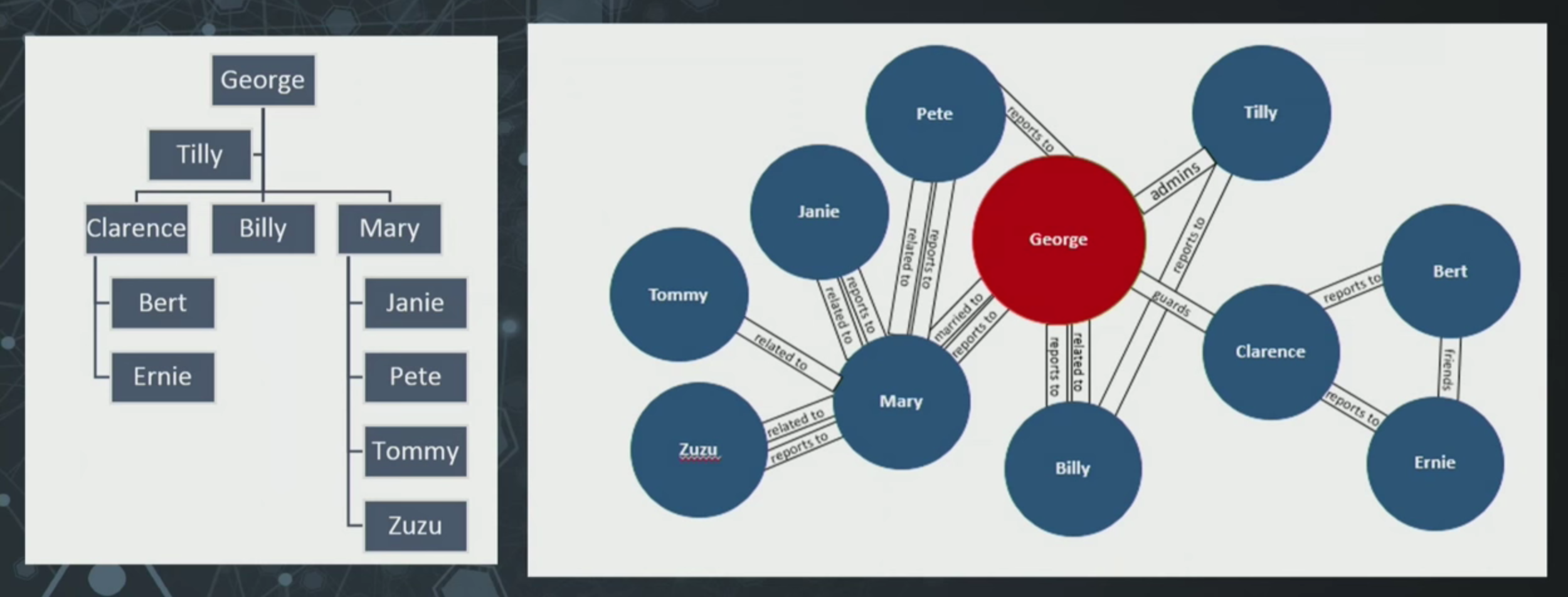 By Neo4j Graph Database Platform -
2015-12-23
By Neo4j Graph Database Platform -
2015-12-23
Watch (or read) Senior Project Manager Karen Lopez’s GraphConnect presentation on the signs that your data is actually a graph and needs a graph database.
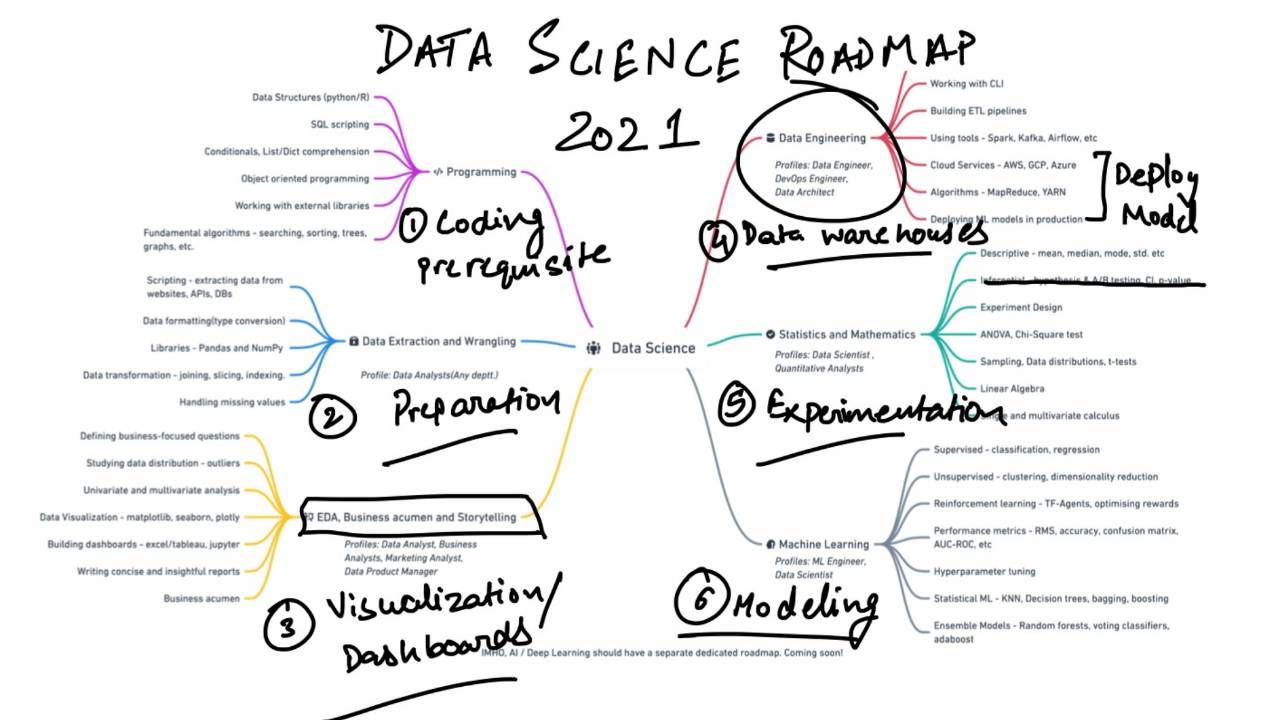 By freeCodeCamp.org -
2021-01-12
By freeCodeCamp.org -
2021-01-12
Although nothing really changes but the date, a new year fills everyone with the hope of starting things afresh. If you add in a bit of planning, some well-envisioned goals, and a learning roadmap, yo ...
 By Google Cloud Blog -
2021-01-22
By Google Cloud Blog -
2021-01-22
See how ecommerce company Richardo.ch chose Cloud Bigtable as its database to complement its data warehouse and save costs with scalability.
 By Google Cloud Blog -
2021-03-12
By Google Cloud Blog -
2021-03-12
Among the best ways to prevent data loss are to modify, delete, or never collect the data in the first place.
 By Medium -
2020-12-01
By Medium -
2020-12-01
If I learned anything from working as a data engineer, it is that practically any data pipeline fails at some point. Broken connection, broken dependencies, data arriving too late, or some external…