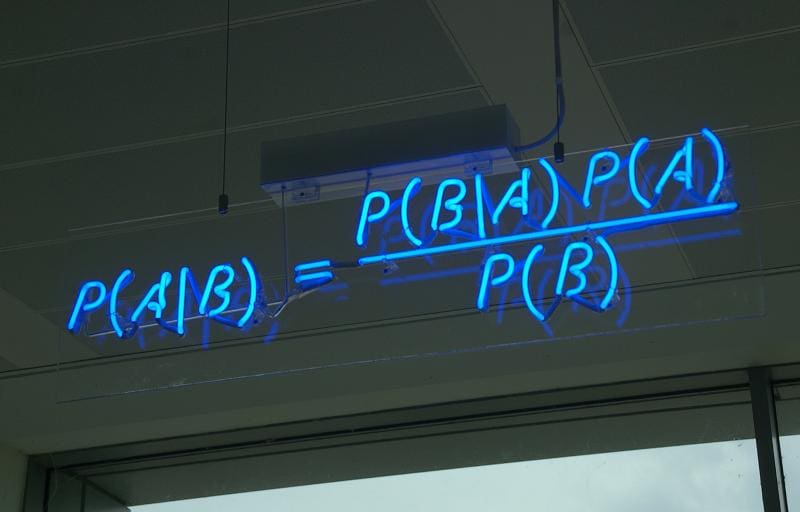By CMSWire.com -
2021-03-16
By CMSWire.com -
2021-03-16
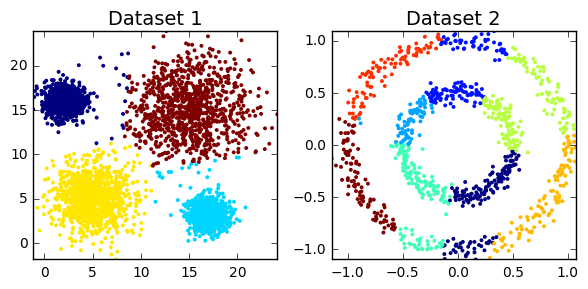
Not all data is valuable or actionable and discerning which is which can be hard. Learn to craft a successful data strategy that can help a brand learn to swim.
 By Docs -
2021-01-24
By Docs -
2021-01-24
Describes benefits, challenges, and best practices for Big Data architectures on Azure.
 By Gradient Flow -
2021-02-02
By Gradient Flow -
2021-02-02
Metadata will be the foundation for data governance solutions, data catalogs, and other enterprise data systems. By Assaf Araki and Ben Lorica. Introduction As companies embrace digital technologie…
 By KDnuggets -
2020-10-13
By KDnuggets -
2020-10-13
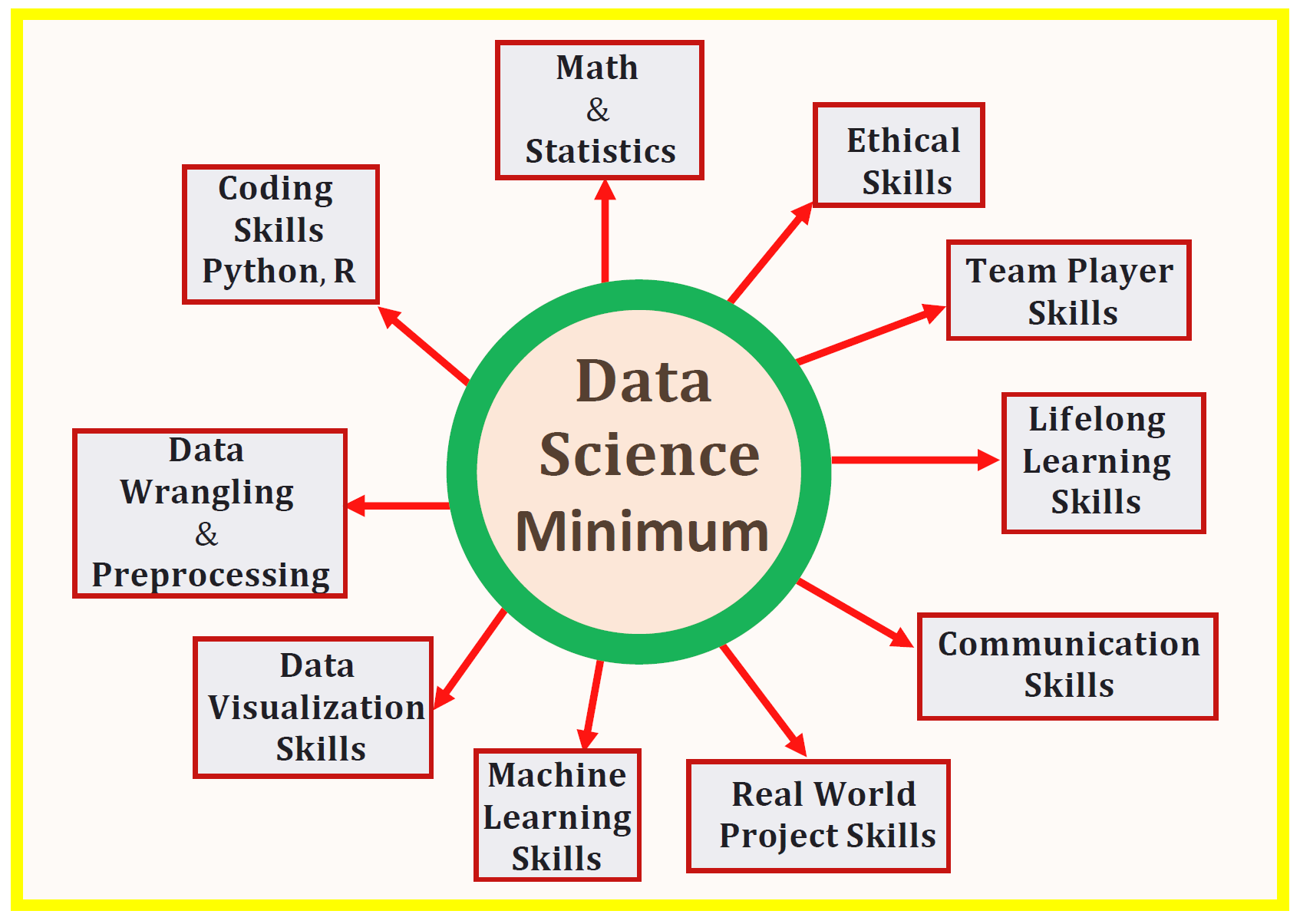
Data science is ever-evolving, so mastering its foundational technical and soft skills will help you be successful in a career as a Data Scientist, as well as pursue advance concepts, such as deep lea ...
 By Ai+ Training -
2021-01-26
By Ai+ Training -
2021-01-26
Join AI+ Subscription to learn at ODSC Training about Machine Learning & Modelling
 By Medium -
2020-12-08
By Medium -
2020-12-08
As you know, data science, and more specifically machine learning, is very much en vogue now, so guess what? I decided to enroll in a MOOC to become fluent in data science. But when you start with a…