 By KDnuggets -
2021-02-09
By KDnuggets -
2021-02-09
Attention is a powerful mechanism developed to enhance the performance of the Encoder-Decoder architecture on neural network-based machine translation tasks. Learn more about how this process works an ...
 By Google AI Blog -
2020-10-23
By Google AI Blog -
2020-10-23
Posted by Krzysztof Choromanski and Lucy Colwell, Research Scientists, Google Research Transformer models have achieved state-of-the-art...
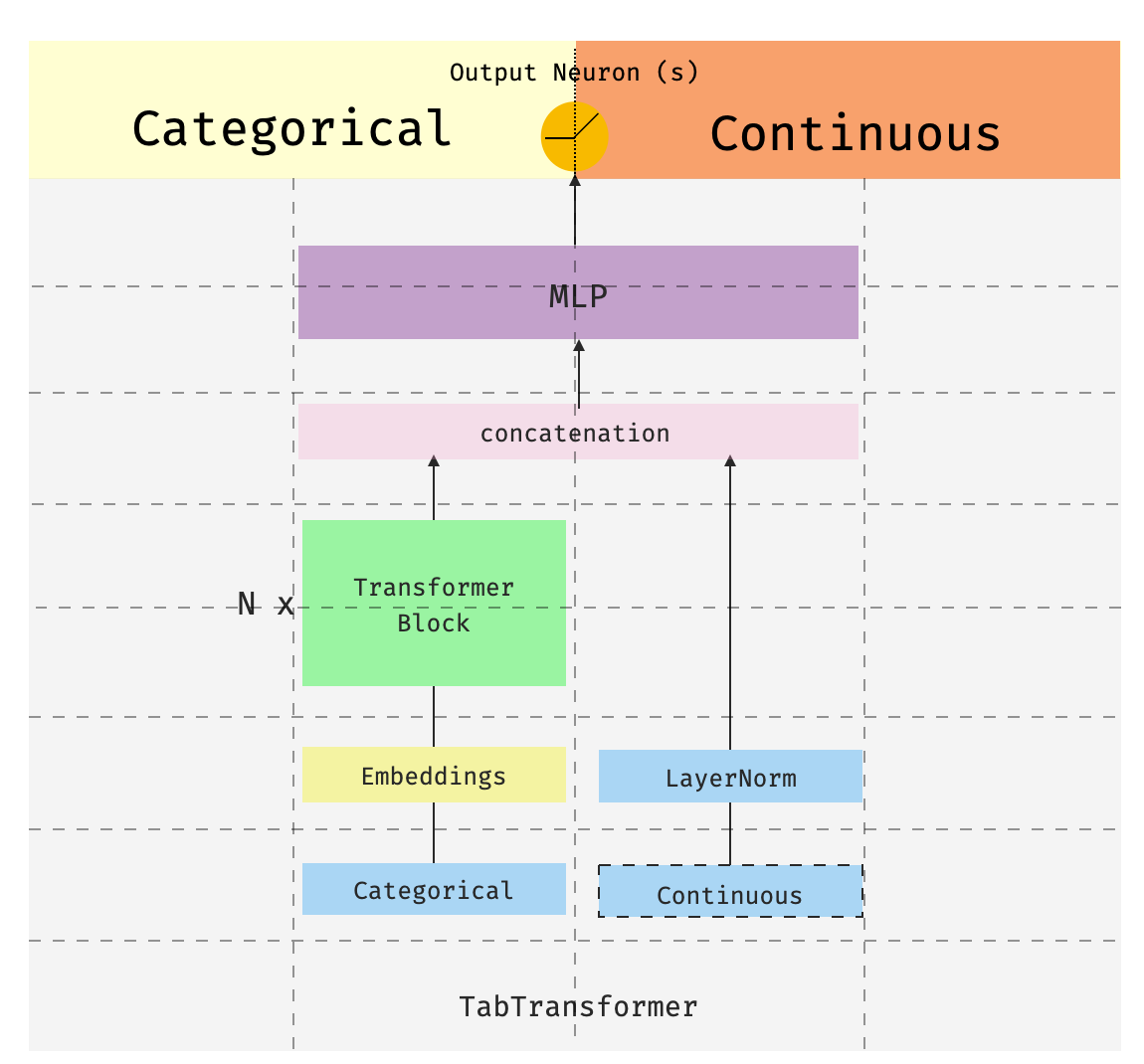 By Medium -
2021-02-22
By Medium -
2021-02-22
This is the third of a series of posts introducing pytorch-widedeepa flexible package to combine tabular data with text and images (that could also be used for “standard” tabular data alone). The…
 By MachineCurve -
2021-02-15
By MachineCurve -
2021-02-15
Machine Translation with Python and Transformers - learn how to build an easy pipeline for translation and to extend it to more languages.
 By TOPBOTS -
2021-02-04
By TOPBOTS -
2021-02-04
An overview of the architecture and the implementation details of the most important Deep Learning algorithms for Time Series Forecasting.
 By Medium -
2021-03-10
By Medium -
2021-03-10
Sentiment analysis is typically limited by the length of text that can be processed by transformer models like BERT. We will learn how to work around this.