By KDnuggets -
2021-03-11
By KDnuggets -
2021-03-11
CLIP is a bridge between computer vision and natural language processing. I'm here to break CLIP down for you in an accessible and fun read! In this post, I'll cover what CLIP is, how CLIP works, and ...
 By tensorflow -
2020-10-27
By tensorflow -
2020-10-27
Urban legend says that Mona Lisa's eyes will follow you as you move around the room. This interactive digital portrait brings the phenomenon to life..
 By Medium -
2020-12-02
By Medium -
2020-12-02
Semantic segmentation is the task of predicting the class of each pixel in an image. This problem is more difficult than object detection…
 By Medium -
2021-02-22
By Medium -
2021-02-22
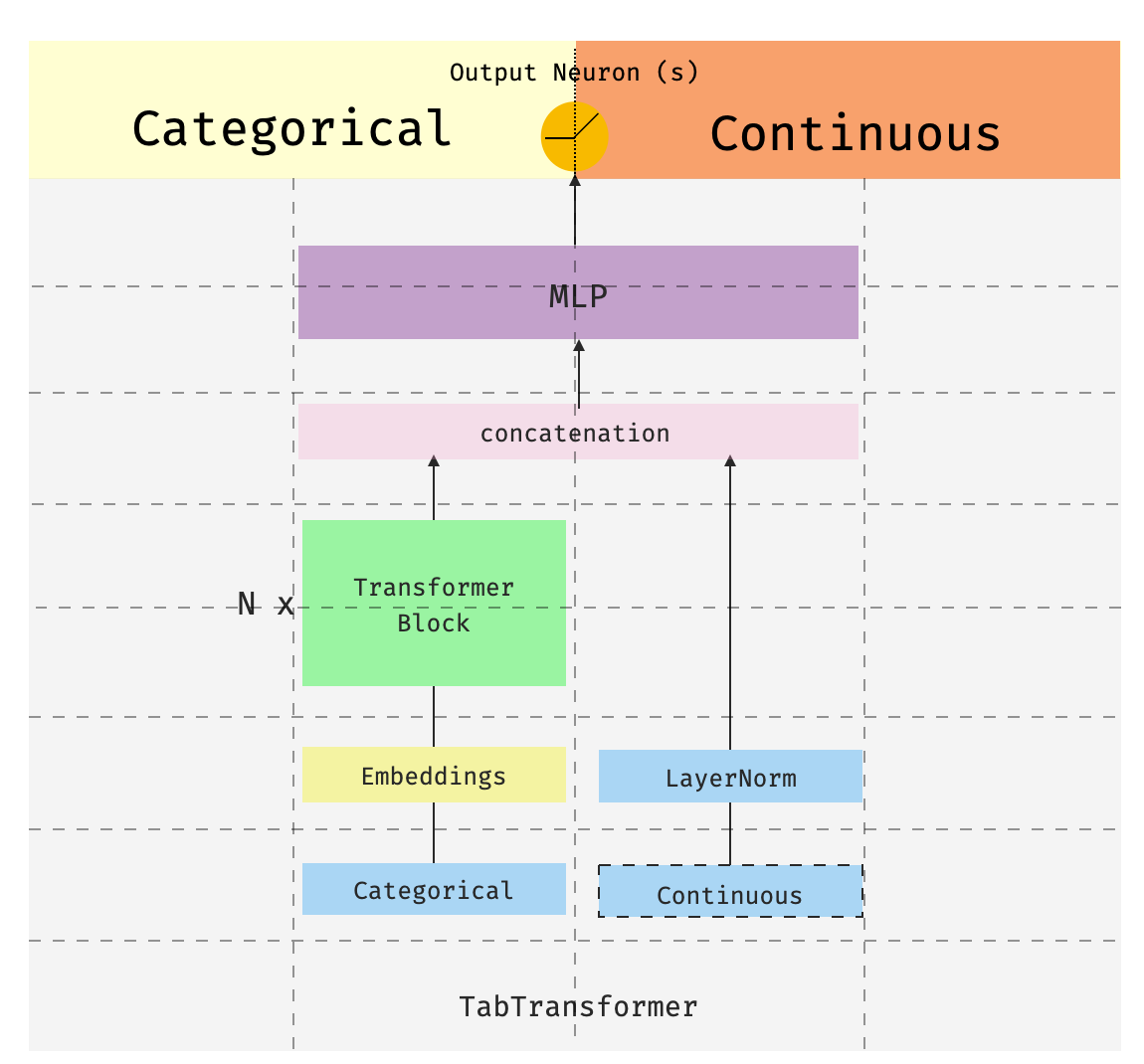
This is the third of a series of posts introducing pytorch-widedeepa flexible package to combine tabular data with text and images (that could also be used for “standard” tabular data alone). The…
 By GitHub -
2020-12-07
By GitHub -
2020-12-07
📖 👆🏻 Links Detector makes printed links clickable via your smartphone camera. No need to type a link in, just scan and click on it. - trekhleb/links-detector
 By The Gradient -
2020-11-21
By The Gradient -
2020-11-21
A broad overview of the sub-field of machine learning interpretability; conceptual frameworks, existing research, and future directions.