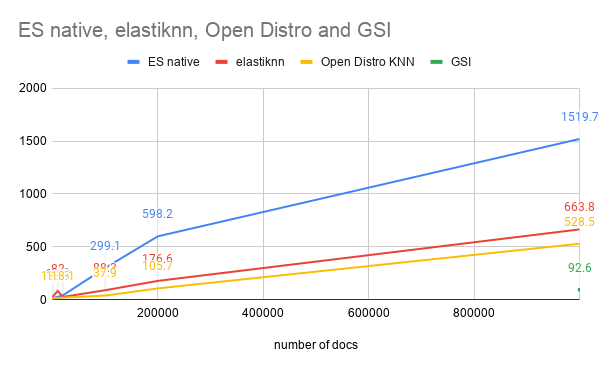
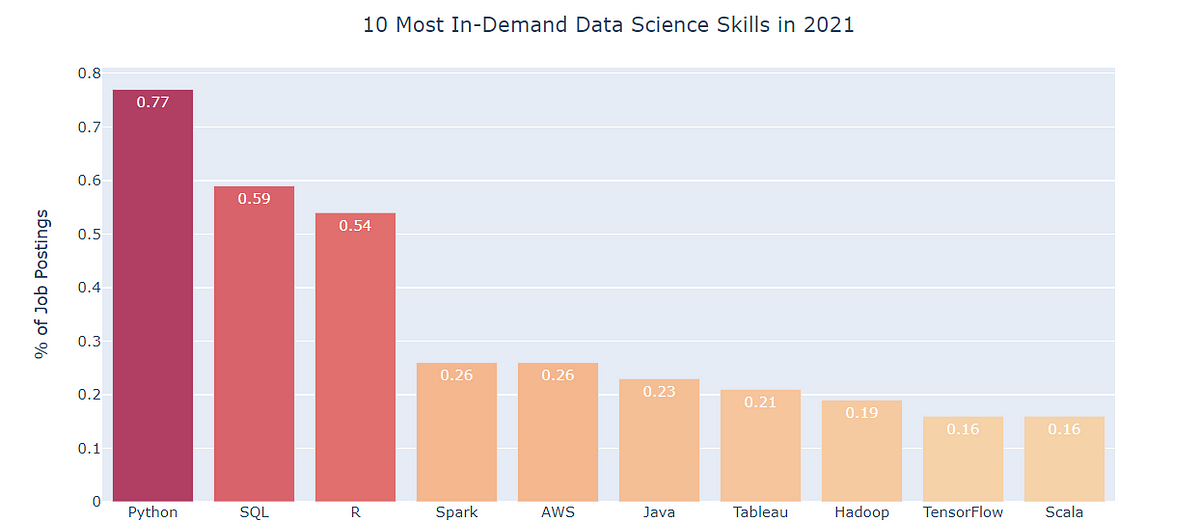
By huggingface -
2021-03-12
By huggingface -
2021-03-12
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
 By Medium -
2020-12-03
By Medium -
2020-12-03
This tutorial covers the entire ML process, from data ingestion, pre-processing, model training, hyper-parameter fitting, predicting and storing the model for later use. We will complete all these…
 By Joe Davison Blog -
2020-05-29
By Joe Davison Blog -
2020-05-29
State-of-the-art NLP models for text classification without annotated data
 By MachineCurve -
2021-02-02
By MachineCurve -
2021-02-02
Explanations and code examples showing you how to use K-fold Cross Validation for Machine Learning model evaluation/testing with PyTorch.
 By Medium -
2021-02-16
By Medium -
2021-02-16
If you have worked with any kind of forecasting models, you will know how laborious it can be at times especially when trying to predict multiple variables. From identifying if a time-series is…
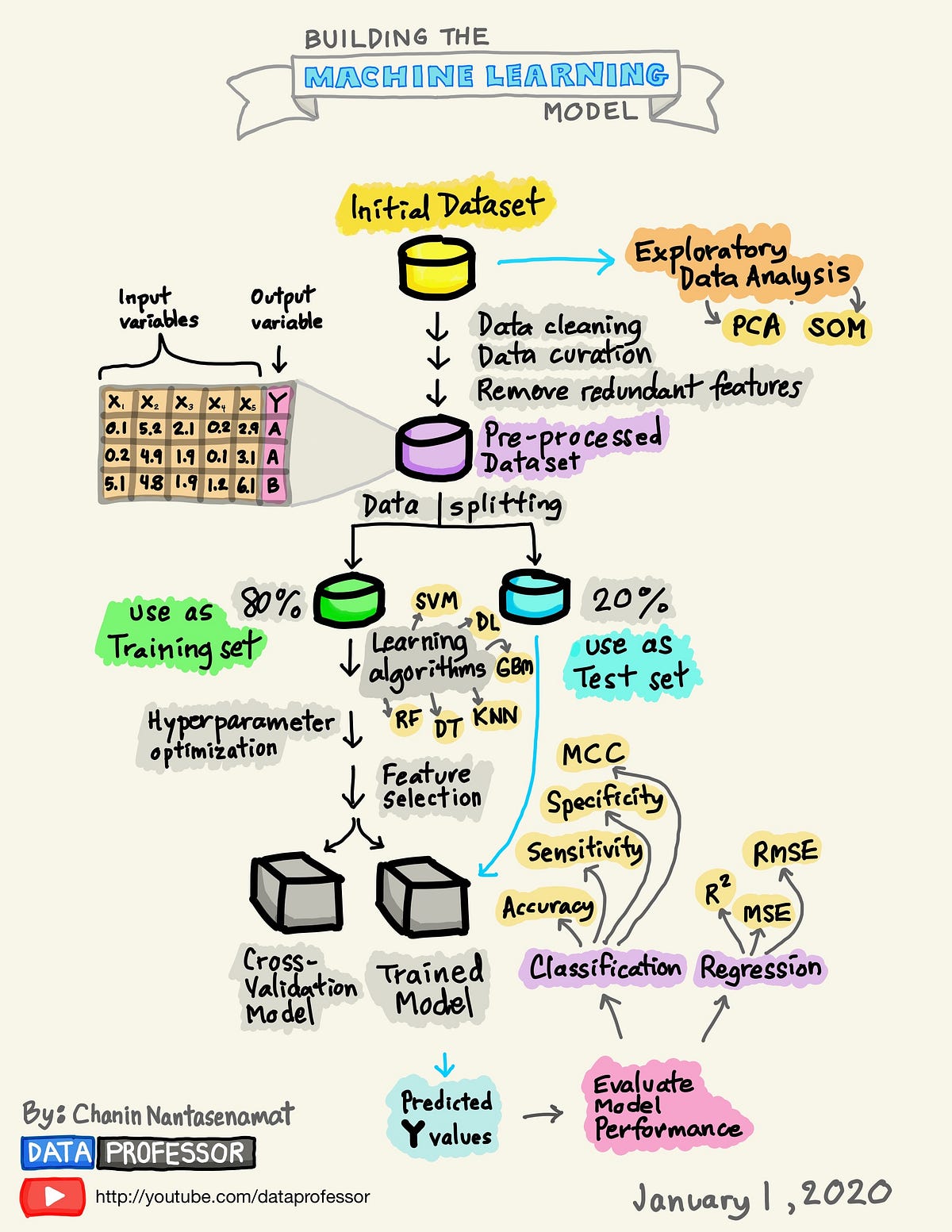 By Medium -
2020-07-25
By Medium -
2020-07-25
A Visual Guide to Learning Data Science