 By Medium -
2020-11-29
By Medium -
2020-11-29
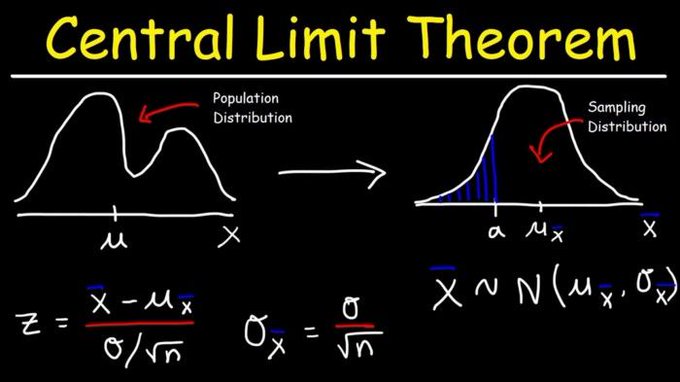
Note: Here I will try to cover the idea of the Central Limit Theorem, and it’s significance in statistical analysis, and how it is useful…
 By Medium -
2020-09-28
By Medium -
2020-09-28
Finding machine learning datasets is tenacious indeed, but it doesn’t have to be! In this article, we’ve shared multiple datasets you can…
 By tryolabs -
2021-01-28
By tryolabs -
2021-01-28
Introduction to Personal data anonymization essential aspects: formats, techniques, and process. Finally, we summarize how data anonymization affects Machine Learning models
 By Medium -
2020-12-10
By Medium -
2020-12-10
A/B testing is a tool that allows to check whether a certain causal relationship holds. For example, a data scientist working for an e-commerce platform might want to increase the revenue by…
 By Medium -
2020-12-06
By Medium -
2020-12-06
Simple statistics can get the job done without spending money and time on expensive computational routines
 By MachineCurve -
2021-02-02
By MachineCurve -
2021-02-02
Explanations and code examples showing you how to use K-fold Cross Validation for Machine Learning model evaluation/testing with PyTorch.