 By Medium -
2020-07-25
By Medium -
2020-07-25
A Visual Guide to Learning Data Science
 By Medium -
2020-12-08
By Medium -
2020-12-08
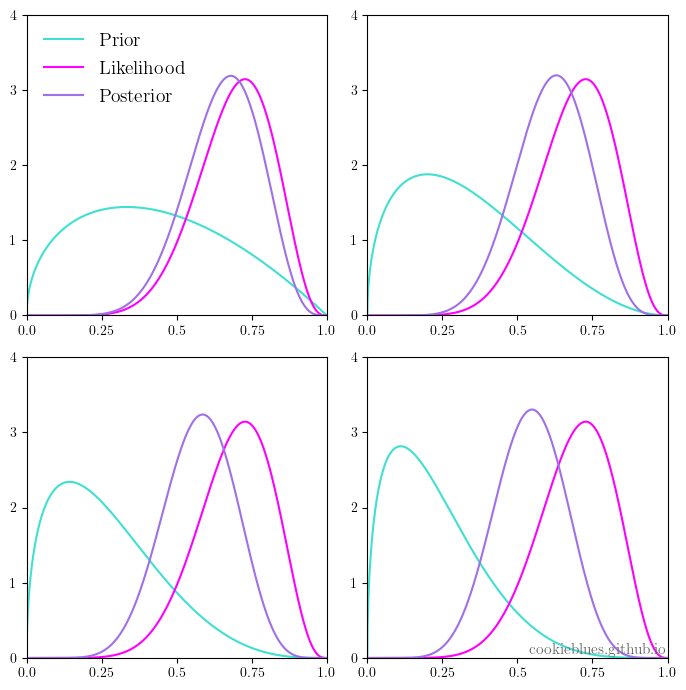
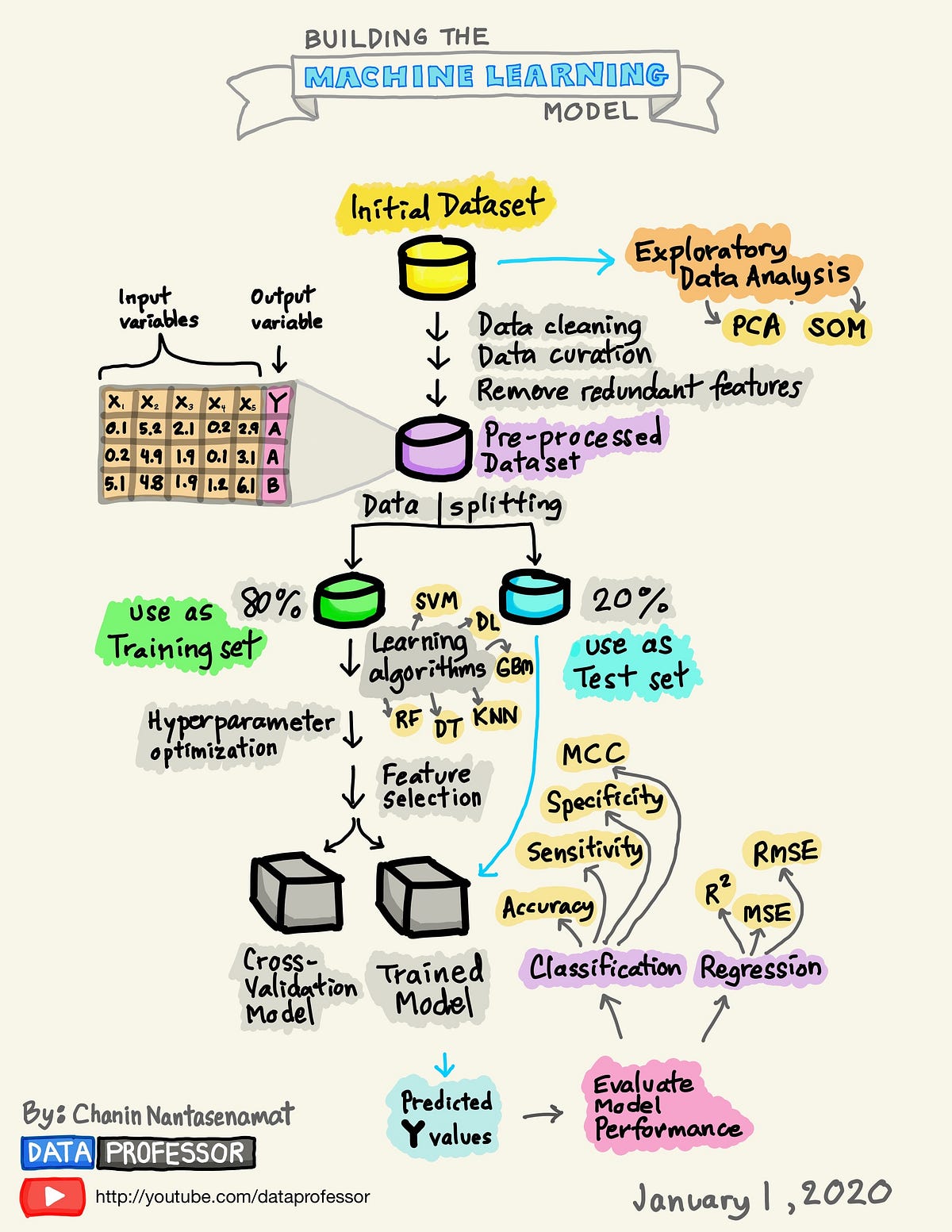
As you know, data science, and more specifically machine learning, is very much en vogue now, so guess what? I decided to enroll in a MOOC to become fluent in data science. But when you start with a…
 By freeCodeCamp.org -
2021-01-12
By freeCodeCamp.org -
2021-01-12
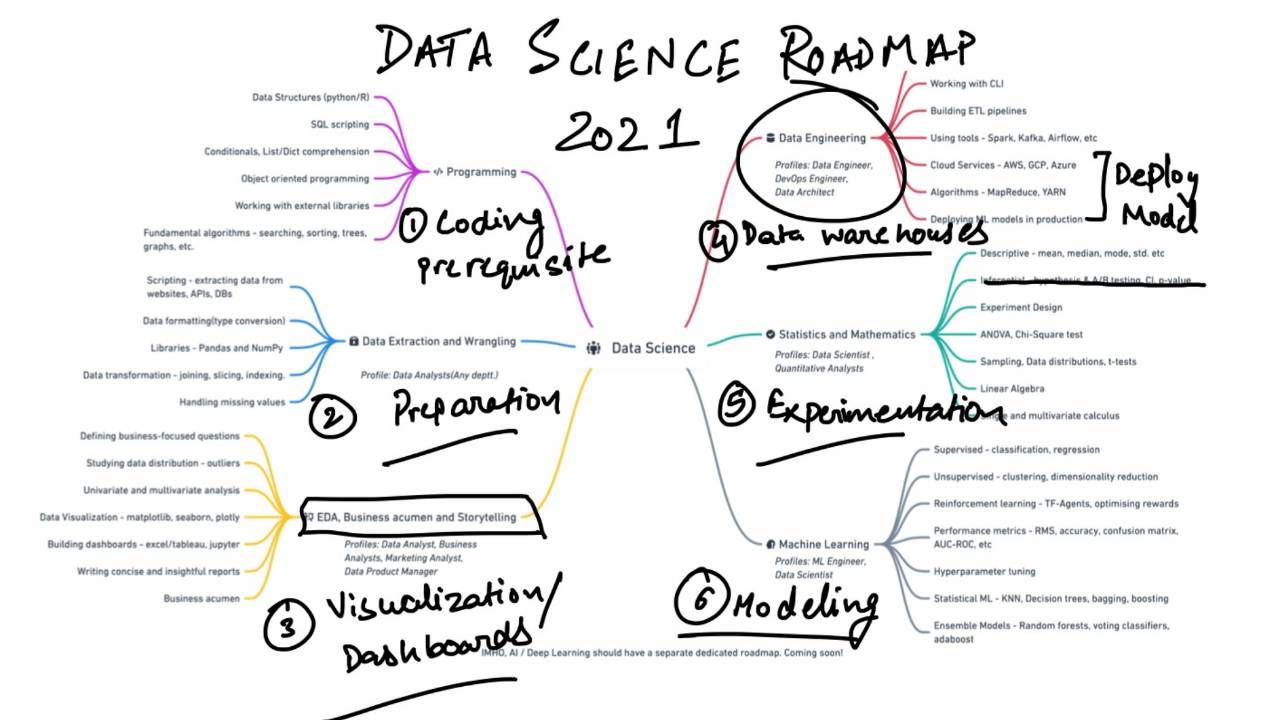
Although nothing really changes but the date, a new year fills everyone with the hope of starting things afresh. If you add in a bit of planning, some well-envisioned goals, and a learning roadmap, yo ...
 By Joe Davison Blog -
2020-05-29
By Joe Davison Blog -
2020-05-29
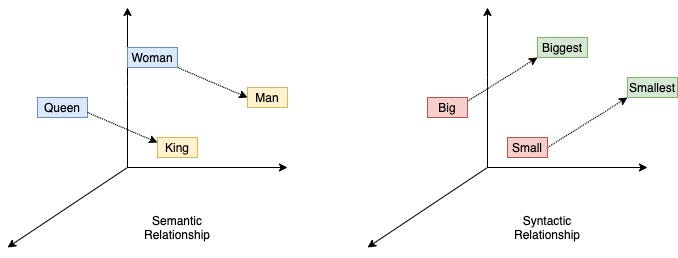
State-of-the-art NLP models for text classification without annotated data
 By Medium -
2020-12-25
By Medium -
2020-12-25
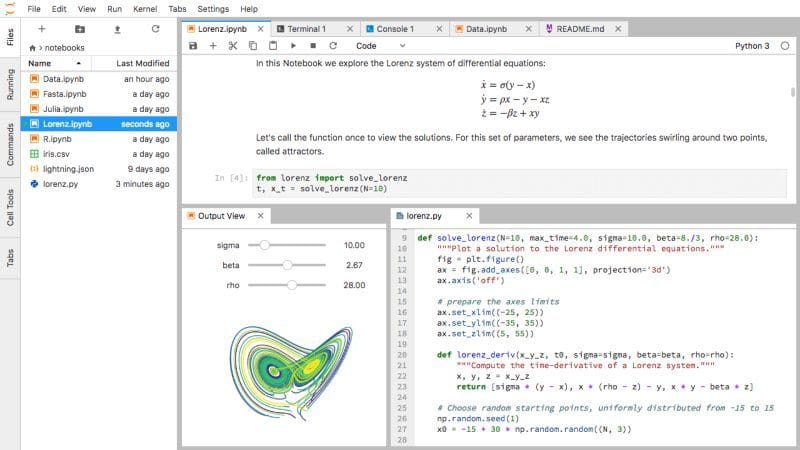
In my previous TDS article I described about the Machine Learning variant of Deep Hybrid Learning and how easily it can be applied for image data. If you are someone who is new to the concept of Deep…
By KDnuggets -
2020-12-15
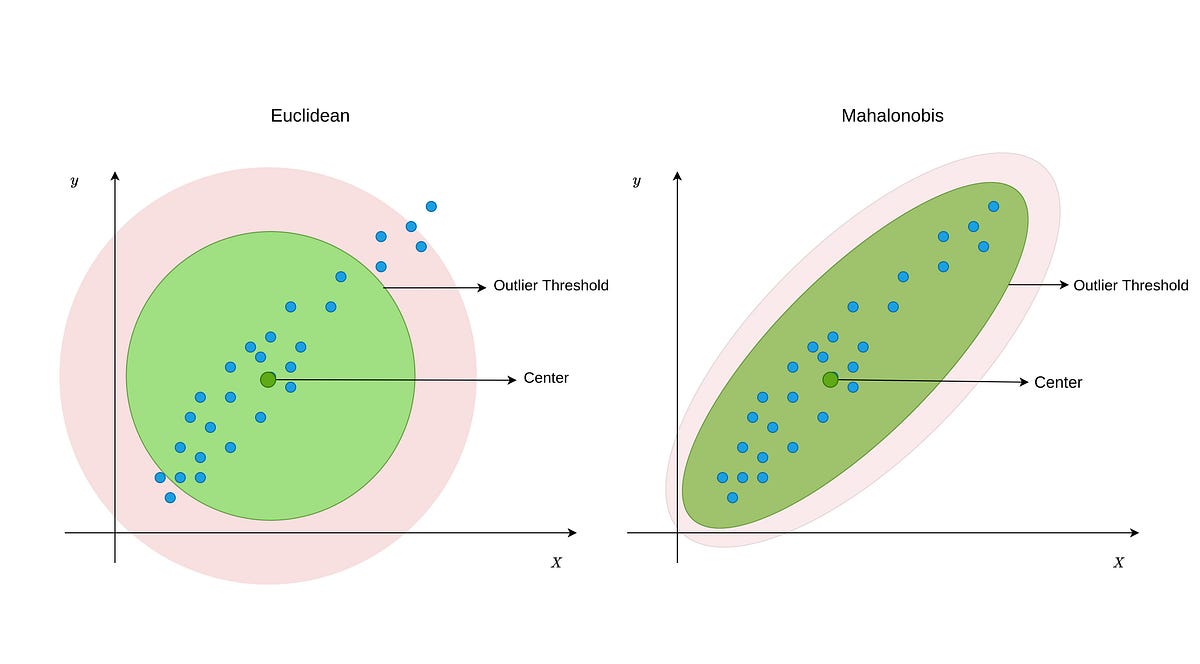
An extensive overview of Active Learning, with an explanation into how it works and can assist with data labeling, as well as its performance and potential limitations.