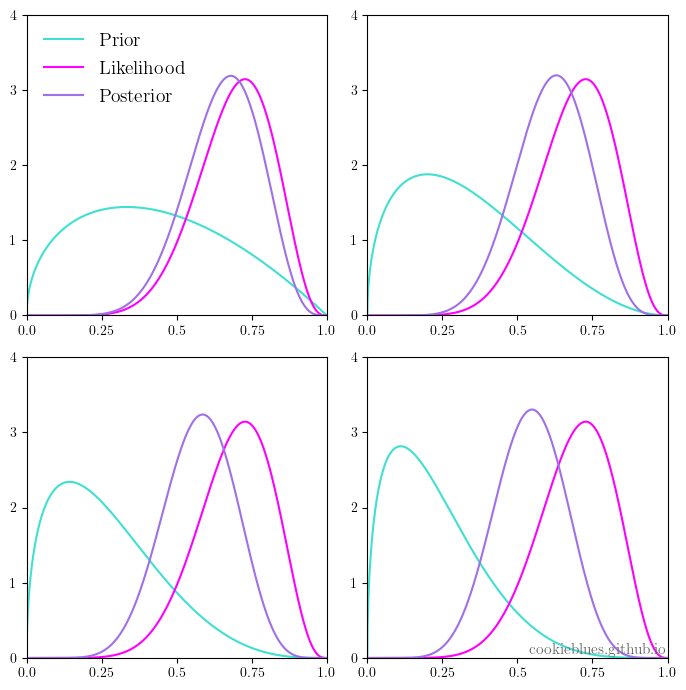
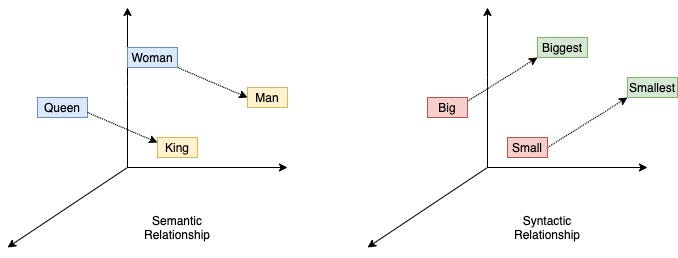
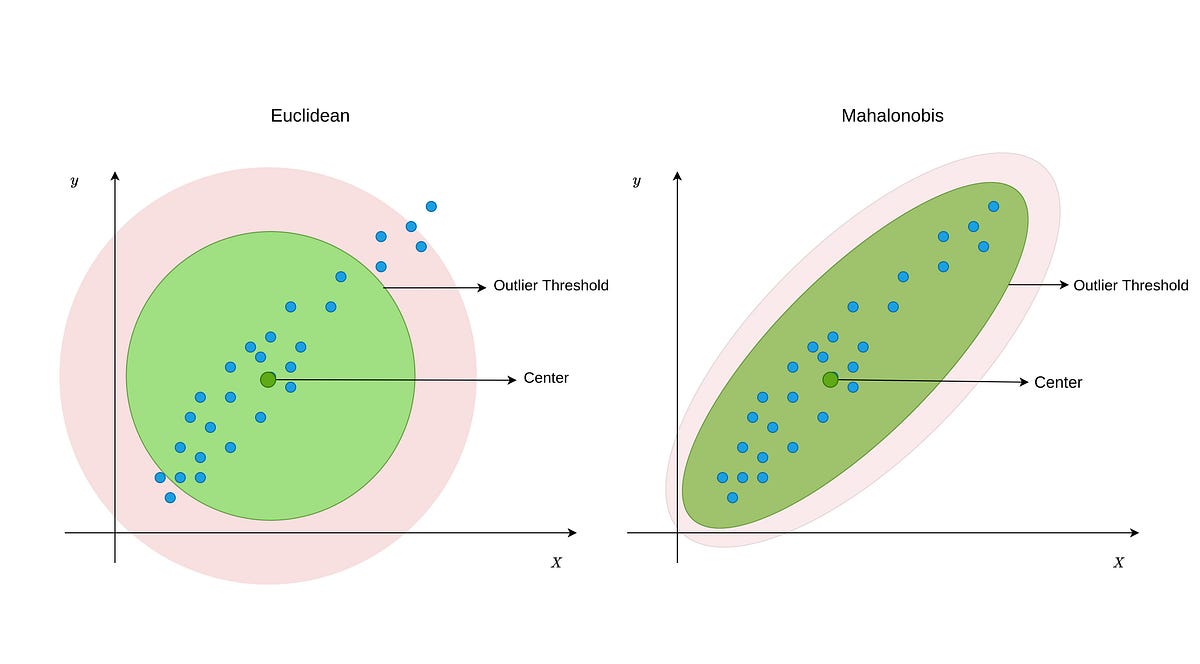
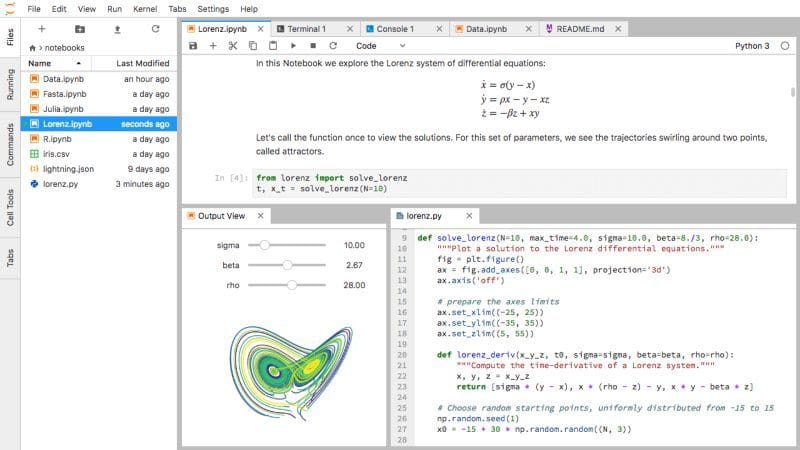
By Spotify Engineering -
2021-02-11
By Spotify Engineering -
2021-02-11
Spotify’s official technology blog
 By Medium -
2020-09-16
By Medium -
2020-09-16
There are a lot of ETL tools out there and sometimes they can be overwhelming, especially when you simply want to copy a file from point A to B. So today, I am going to show you how to extract a CSV…
 By Medium -
2021-01-31
By Medium -
2021-01-31
I always liked city maps and a few weeks ago I decided to build my own artistic versions of it. After googling a little bit I discovered this incredible tutorial written by Frank Ceballos. It is a…
 By Amazon Web Services, Inc. -
2021-03-12
By Amazon Web Services, Inc. -
2021-03-12
Amazon Transcribe is an automatic speech recognition (ASR) service that makes it easy for developers to add speech to text capability to their applications
 By Medium -
2021-02-15
By Medium -
2021-02-15
Amazon MWAA (Managed Workflow for Apache Airflow) was released by AWS at the end of 2020. This brand new service provides a managed solution to deploy Apache Airflow in the cloud, making it easy to…
 By DEV Community -
2021-01-22
By DEV Community -
2021-01-22
Although most developers are shifting to serverless and containerized architectures for building thei...